NEUE FRAGE 88
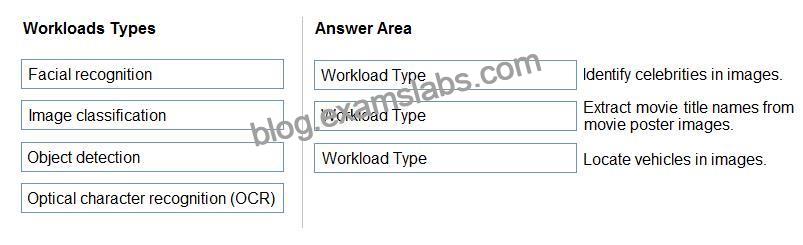
Ordnen Sie die Arten der Computer Vision den entsprechenden Szenarien zu.
Um zu antworten, ziehen Sie den entsprechenden Workload-Typ aus der linken Spalte in das entsprechende Szenario auf der rechten Seite. Jeder Systemlasttyp kann einmal, mehrmals oder gar nicht verwendet werden.
HINWEIS: Jede richtige Auswahl ist einen Punkt wert.

Erläuterung
Kasten 1: Gesichtserkennung
Gesichtserkennung, die Gesichter und Attribute in einem Bild wahrnimmt; Personenidentifikation, die eine Person in Ihrer privaten Datenbank mit bis zu 1 Million Personen abgleicht; Erkennung wahrgenommener Emotionen, die eine Reihe von Gesichtsausdrücken wie Freude, Verachtung, Neutralität und Angst erkennt; und Erkennung und Gruppierung ähnlicher Gesichter in Bildern.
Feld 2: OCR
Kasten 3: Erkennung von Einsprüchen
Die Objekterkennung ähnelt der Markierung, aber die API gibt die Bounding-Box-Koordinaten (in Pixeln) für jedes gefundene Objekt zurück. Wenn ein Bild beispielsweise einen Hund, eine Katze und eine Person enthält, listet der Vorgang "Erkennen" diese Objekte zusammen mit ihren Koordinaten im Bild auf. Sie können diese Funktion verwenden, um die Beziehungen zwischen den Objekten in einem Bild zu verarbeiten. Außerdem können Sie damit feststellen, ob es mehrere Instanzen desselben Tags in einem Bild gibt.
Die Erkennungs-API vergibt Tags auf der Grundlage der im Bild identifizierten Objekte oder Lebewesen. Derzeit gibt es keine formale Beziehung zwischen der Taxonomie für die Markierung und der Taxonomie für die Objekterkennung. Auf konzeptioneller Ebene findet die Detect-API nur Objekte und Lebewesen, während die Tag-API auch kontextbezogene Begriffe wie
"indoor", die nicht mit Bounding Boxes lokalisiert werden können.
Referenz:
https://azure.microsoft.com/en-us/services/cognitive-services/face/
https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/concept-object-detection







Eine Antwort hinterlassen