NEUE FRAGE 64
Was ist die richtige Reihenfolge bei der Migration eines Datensatzes von Document Manager zu einem Modern Project? Anweisungen:
Ziehen Sie die Beschreibung auf der linken Seite und legen Sie sie auf dem richtigen Schritt auf der rechten Seite ab.


Erläuterung:
Um die Schritte in der richtigen Reihenfolge für die Migration eines Datensatzes aus dem Dokumentenmanager in ein Modernes Projekt zu organisieren, analysiere ich die Anweisungen und ordne die Schritte dann entsprechend zu. Hier ist die logische Reihenfolge auf der Grundlage der Beschreibungen:
* Schritt 1: Navigieren Sie zu dem Projekt, in das Sie Daten importieren möchten, und öffnen Sie es. Wählen Sie einen bereits vorhandenen benutzerdefinierten Dokumenttyp oder erstellen Sie einen neuen.
* Schritt 2: Wählen Sie "Hochladen" und wählen Sie die ZIP-Datei, die aus dem klassischen Projekt exportiert wurde. Warten Sie, bis der Upload abgeschlossen ist.
* Schritt 3: Gehen Sie zu dem Dokumenttyp, den Sie exportieren möchten, und wählen Sie "Dokumenttyp öffnen".
* Schritt 4: Wählen Sie in der Dropdown-Liste "Dokumente filtern" die Option "Trainings- und Validierungssatz". Wählen Sie .
"Exportieren".
* Schritt 5: Lassen Sie "Aktuelle Suchergebnisse" ausgewählt und geben Sie einen Namen für Ihren Exportauftrag ein. Wählen Sie
"Herunterladen".
Dies sollte den korrekten sequentiellen Prozess der Migration eines Datensatzes von Document Manager zu einem Modern Project widerspiegeln.

NEUE FRAGE 67
Wie werden UiPath RPA und AI Center zur Prozessverbesserung eingesetzt?
NEUE FRAGE 68
Was ist einer der Zwecke der Config-Datei in der UiPath Document Understanding Template?
Die Config-Datei in der UiPath Document Understanding Template ist eine JSON-Datei, die verschiedene Parameter und Werte enthält, die das Verhalten und die Funktionalität der Vorlage steuern. Einer der Zwecke der Config-Datei ist die Speicherung der API-Schlüssel und Authentifizierungsdaten für den Zugriff auf externe Dienste, wie die Document Understanding API, die Computer Vision API, die Form Recognizer API und die Text Analysis API. Diese Dienste werden von der Vorlage verwendet, um Dokumentenklassifizierung, Datenextraktion und Datenvalidierung durchzuführen. Die Config-Datei ermöglicht es dem Benutzer außerdem, die Vorlage an seine Bedürfnisse anzupassen, z. B. die Human-in-the-Loop-Validierung zu aktivieren oder zu deaktivieren, den Wiederholungsmechanismus festzulegen, die benutzerdefinierte Erfolgslogik zu definieren und die Taxonomie der Dokumenttypen anzugeben.
Referenzen: Dokument Verstehender Prozess: Studio-Vorlage, Automation Suite - Dokument Verständnis der Konfigurationsdatei
NEUE FRAGE 69
Was ist das Document Object Model (DOM) im Zusammenhang mit dem Verstehen von Dokumenten?
Das Document Object Model (DOM) ist eine Datendarstellung der Objekte, die die Struktur und den Inhalt eines Dokuments im Web umfassen1. Im Kontext von Document Understanding ist das DOM ein JSON-Objekt, das von der Aktivität "Digitize Document" erzeugt wird, die die UiPath Document OCR-Engine verwendet, um den Text und die Layout-Informationen aus dem Eingabedokument zu extrahieren2. Das DOM enthält die folgenden Eigenschaften für jedes Dokument3:
* Name: Der Name der Dokumentendatei.
* contentType: Der MIME-Typ der Dokumentendatei, z. B. application/pdf oder image/jpeg.
* textLength: Die Anzahl der Zeichen im Text des Dokuments.
* Seiten: Ein Array von Objekten, die jeweils eine Seite des Dokuments darstellen. Jedes Seitenobjekt hat die folgenden Eigenschaften:
* pageNumber: Die Nummer der Seite, beginnend mit 1.
* Drehung: Der Drehwinkel der Seite, in Grad. Ein positiver Wert bedeutet eine Drehung im Uhrzeigersinn, ein negativer Wert eine Drehung gegen den Uhrzeigersinn.
* Sprache: Der Sprachcode der Seite, z. B. en oder fr.
* Inhalt: Ein Array von Objekten, die jeweils ein Wort oder eine Zeile in der Seite darstellen. Jedes Inhaltsobjekt hat die folgenden Eigenschaften:
* Typ: Der Typ des Inhalts, entweder Wort oder Zeile.
* Text: Der Text des Inhalts.
* boundingBox: Ein Array mit vier Zahlen, die die Koordinaten der linken oberen und rechten unteren Ecke des Inhalts im Format [x1, y1, x2, y2] angeben. Die Koordinaten sind relativ zur Seite, mit dem Ursprung in der linken oberen Ecke, und die Einheit ist Pixel.
* Vertrauen: Eine Zahl zwischen 0 und 1, die den Vertrauensgrad der OCR-Engine bei der Erkennung des Inhalts angibt.
Das DOM kann als Input für andere Aktivitäten im Document Understanding Framework verwendet werden, z. B. für Classify Document Scope, Data Extraction Scope oder Export Extraction Results. Das DOM kann auch mit Programmiercode wie JavaScript oder Python manipuliert werden, um benutzerdefinierte Operationen mit den Dokumentdaten durchzuführen.
Referenzen:
1: Einführung in das DOM - Web APIs | MDN 2: Dokument digitalisieren 3: Document Object Model
NEUE FRAGE 70
Was ist die richtige Reihenfolge beim Hochladen eines aus dem UiPath AI Center exportierten Pakets?
Anweisungen: Ziehen Sie die Schritte auf der "linken Seite" und legen Sie sie auf der "rechten Seite" in der richtigen Reihenfolge ab.


Erläuterung:
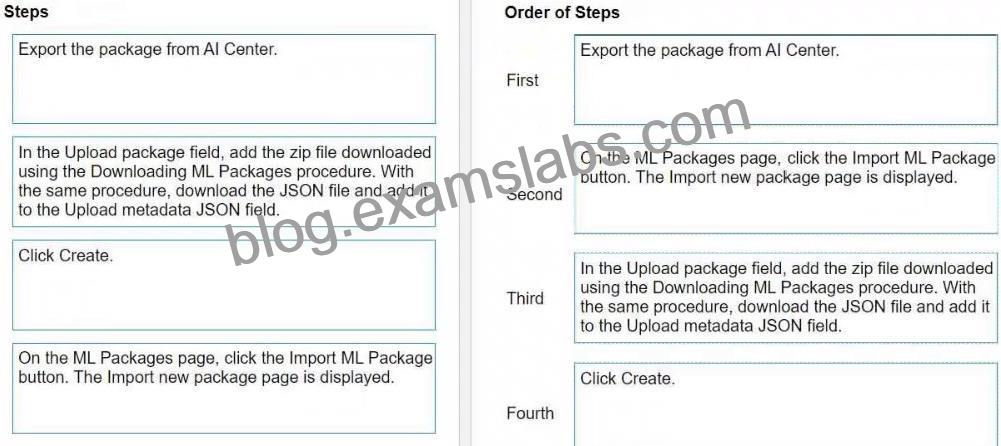
* Exportieren Sie das Paket aus dem AI Center. Dies ist der erste Schritt, in dem Sie das zu verschiebende Paket vorbereiten.
* Klicken Sie auf der Seite ML-Pakete auf die Schaltfläche ML-Paket importieren. In diesem Schritt beginnen Sie mit dem Import des von Ihnen exportierten Pakets.
* Fügen Sie im Feld Paket hochladen die Zip-Datei hinzu, die Sie über das Verfahren ML-Pakete herunterladen heruntergeladen haben. Nach dem Start des Importvorgangs laden Sie das eigentliche Paket hoch.
* Klicken Sie auf Erstellen. Dies ist der letzte Schritt, mit dem Sie den Hochladevorgang Ihres ML-Pakets abschließen.
Bitte führen Sie diese Schritte im UiPath AI Center durch, um Ihr exportiertes Paket korrekt hochzuladen.
NEUE FRAGE 76
Für welche Art von Dokumenten wird die Verwendung des Form Extractor empfohlen?
Der Formularextraktor in UiPath eignet sich am besten für Dokumente, die ein festes oder nicht veränderliches Format haben. Das bedeutet, dass Dokumente, bei denen das Layout konsistent und vorhersehbar ist, wie z. B. standardisierte Formulare oder Rechnungen, ideal für diese Extraktionsmethode sind. Der Formularextraktor verwendet vordefinierte Vorlagen, die Datenfelder auf der Grundlage ihrer Position zuordnen, so dass er sich sehr gut für die Extraktion von Daten aus Dokumenten eignet, deren Layout wenig oder gar nicht variiert. Er ist nicht gut geeignet für Dokumente mit erheblichen Layout-Variationen, die einen flexibleren Extraktionsansatz erfordern würden, wie z. B. einen Extraktor mit maschinellem Lernen.
(Quelle: UiPath Document Understanding Dokumentation)
NEUE FRAGE 77
Was ist der Unterschied zwischen dem Document Understanding Process und dem Document Understanding Framework?
NEUE FRAGE 78
Was stellen Entitäten in UiPath Communications Mining dar?
Entitäten sind zusätzliche Elemente von strukturierten Daten, die aus den Verbatims extrahiert werden können. Zu den Entitäten gehören Daten wie Geldbeträge, Daten, Währungscodes, Organisationen, Personen, E-Mail-Adressen, URLs sowie viele andere branchenspezifische Kategorien. Entitäten stellen Konzepte, Themen und Absichten dar, die für den geschäftlichen Anwendungsfall relevant sind und zum Filtern, Suchen und Analysieren der Verbatims verwendet werden können.
Referenzen:
* Kommunikation Bergbau - Entitäten
* Communications Mining - Verwendung von Entitäten in Ihrer Anwendung
* Communications Mining - Konfiguration von Entitäten







Eine Antwort hinterlassen